
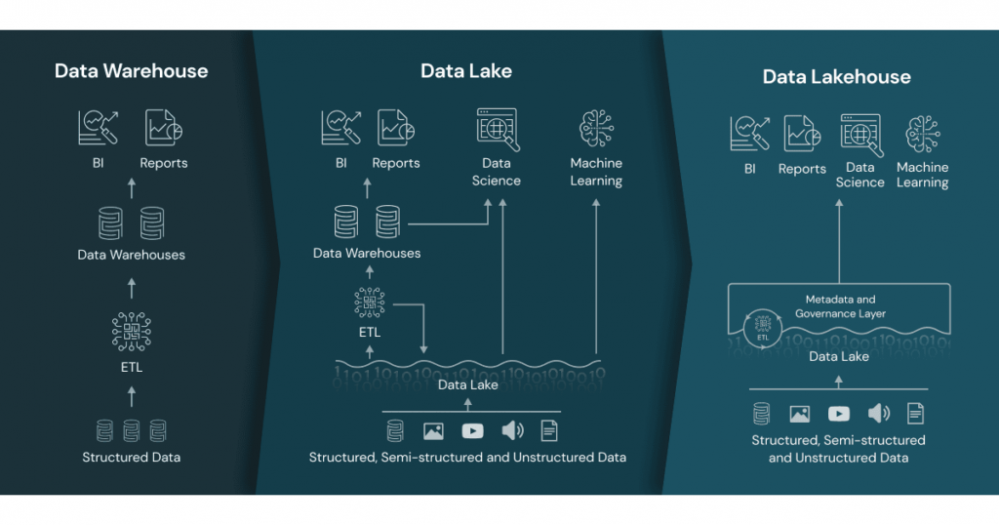
The Data Lakehouse combines the best of Data Warehouse and Data Lakes in one architecture.
The challenge many organizations have, is that they need to analyze all sorts of data, coming from many different places and in massive volumes. Some of the data is structured transaction-based, some of it is semi-structured such as email for example, and some is unstructured, for instance: images or video. The lakehouse architecture is a storage AND analytics solution that combines aspects of previous solutions: data lake and data warehouse, to take advantage of their respective strengths.
Data Warehouse
Data warehouses are built to store and manage structured and semi-structured data for SQL-based analytics and business intelligence. While warehouses are great for structured data, a lot of modern enterprises have to deal with unstructured data, semi-structured data, and data with high variety, velocity, and volume. Data warehouses are not suited for many of these use cases, and they are not the most cost-efficient
Data Lake
A data lake is a low-cost, open, durable storage system for any data type – structured, semi-structured, and unstructured. Oftentimes the vast majority of the data of most organizations is stored in cloud data lakes. This approach of storing data in open formats, at a very low cost has enabled organizations to amass large quantities of data in data lakes while avoiding vendor lock-in. At the same time, data lakes have suffered from three main problems – security, quality, and performance. Organizations end up moving data into other systems to make use of the data, usually data warehouses. Quality is also a challenge because it’s hard to prevent data corruption and manage schema changes. As a result, many argue that most data lakes end up becoming data “swamps”.

Data Lakehouse
The Data Lakehouse is an architecture that combines the best elements of data lakes and data warehouses. It implements similar data structures and data management features to those in a data warehouse built on top of existing low-cost data lakes, which often contain more than 90% of the data in the enterprise. A lakehouse gives you data versioning, governance, security, and ACID properties that are needed even for unstructured data. By building on top of a data lake, the Lakehouse stores and manages all existing data in a data lake, including all varieties of data. Lakehouse also natively supports data science and machine learning use cases by providing direct access to data and supporting various ML and Python/R libraries, such as PyTorch or Tensorflow, unlike data warehouses. Thus, Lakehouse provides a single system to manage all of an enterprise’s data while supporting the range of analytics from BI and AI.
Current lakehouses also reduce cost but their performance can still lag data warehouses that have years of investments and real-world deployments behind them but over time lakehouses will close these gaps while retaining the core properties of being simpler, more cost-efficient, and more capable of serving diverse data applications.
Conclusion
In short, a data lakehouse is a data solution concept that combines elements of the data warehouse with those of the data lake. Data lakehouses implement data warehouses’ data structures and management features for data lakes, which are typically more cost-effective for data storage. Data lakehouses are useful to data scientists as they enable machine learning and business intelligence.
Contact us today for a free consultation!


